
On Eventual Consistency and REST
Typically in event-sourced systems (with Command Query Responsibility Segregation) that need to display data to a client, we have three components that must co-operate
- write model that accepts commands and writes events to its event store
- read model that accepts events and returns DTOs to a client
- client (e.g. web browsers) that writes commands to write model and queries read model for DTOs
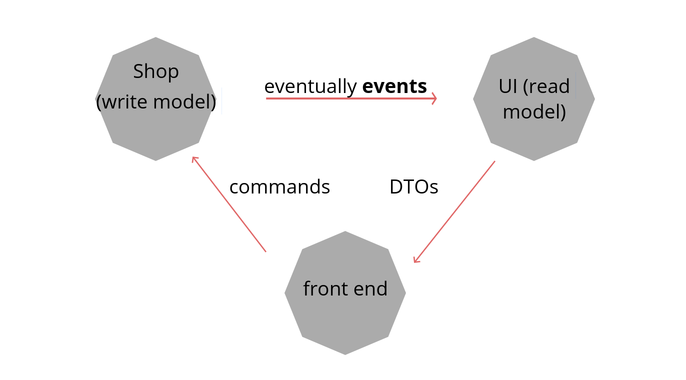
This actually leads us to a situation where we have 3 well defined boundaries with well defined contracts. That means we can easily distribute work among 3 teams. Write model team need to have deep knowledge in the domain, but do not need to touch UI and database (!). Read model team need to perform simple database updates and provide an API for front-end. Front-end in turn must do as usual - request (to write model) and queries (to read model).
Events from the write model can be delivered to subscribers (here, read models) synchronously. That means that we ACK a command if and only if both write model and read model were successfully updated. If one of them fails, client must retry the request. This actually favors Consistency vs. Availability and tangles read model and write model to be backed by the same data source. This solution does not allow us to scale our read models independently from our write model. Another option is to use distributed transactions, which reduce performance. To cut the long story short, synchronous mode reduces flexibility, scalability and autonomy - things that ES/CQRS gave us in the first place.
Having said that, we often prefer asynchronous mode and acknowledging a command as soon as events were produced and saved in the write model. This is also in-line with our natural notion of imperative tense and past tense:
- 1. "DoSomething! (command)"
- 2. "OK, SomethingDone (ACK with event)" or "Nope, piss off!" (N-ACK)
In this mode the information that something was done (event) is delivered to our read model slightly later by the means of read model subscription. The subscription can be fulfilled by the means of a message broker or by pulling the write model by read model for new changes. The way of delivery does not really matter. What matters is that we now favor Availability with the cost of losing Strong Consistency. Our read model will be actually Eventually Consistent - if no further updates are done to the write model, it will return the last updated data. Otherwise, it can return data that is a little stale.
Is that a problem?
Let's consider a read model that is being used by a reporting team to feed their Excel sheets and send e-mails. By the time they update their excel sheet or return from a coffee to check e-mail or go to a printer to fetch the printed version, received data can be already stale. Even though a read model is strongly consistent with the write model, it does not prevent end users from USING this data in eventually consistent way.
Imagine how companies used to work back then without computers. It took time to deliver information on a piece of paper from one desk to another. Everything was eventually consistent. Than we (developers) came and introduced strong consistency and ACID. That is why business people now think of "eventually consistent" data as "incorrect" data. Even when they use their strongly consistent data to print reports and analyze them at home few hours later. Banks worked perfectly fine without computers back then. Moreover, now bank systems are eventually consistent. Even in critical parts of the data, like your account balance. Having said that, eventual consistency is almost always fine. All you need to do is slightly educate users of your system.
But…Read your own Writes
There are some guaranties you would like to ensure. Imagine situation when user issues a command "ChangeHomeAddress" and refreshes the browser. If he is unlucky, new address is not there and he feels like the system is broken. He will probably retry his request. It is HIS update, so he cares about it. He does not care if updates that are consequences of other users actions arrive 1 sec later or earlier. But he would like to see EFFECTS of HIS actions. That guaranty is called "Read your own writes".
How to ensure "Read your own writes" when the read model is asynchronously updated? First let's talk about how events are stored in the write model. Consider we have a ShopItem with UUID. ShopItem produces events in response to a command (e.g. Pay command and ItemPaid event). Produced events are stored in event store (write model). Each event has UUID of a ShopItem, occurred_at date and sequence number. Events related to ShopItem with particular UUID are grouped into so-called Event Steams. Event Stream is responsible for tracking events from one instance of an aggregate. An aggregate in Domain Driven Design terms is a cluster of objects that create a transactional boundary. Aggregate is stored as a series of events in events stream, that means that event stream is our transactional boundary - only one person can write to event-stream at a time (because only one person can modify an aggregate at a time). That means that we can have a version counter for optimistic locking for each of the streams. Each write to an event-stream bumps up version counter or raises optimistic locking exception. That means that when we have 3 events in event stream (with sequence numbers 1, 2 and 3) the version counter of corresponding event stream is 3. In other words, version counter is denormalized value from max sequence number in given event stream.
Let's now go back to our three components: client, write model and read model. We previously said that in asynchronous mode, a command is accepted when events are persisted in write model. That means that when write model returns and ACK to a client, it knows what event it had just written. In particular, he knows what is a version counter (sequence number of last event) of domain item modified by the command. He can return this information to a client, so that client will know what version of domain item was created due to his change. Now the client can include this information when querying read model. He can specify that he EXPECTS to get data at a version equal or greater to the one returned with ACK. Why equal or greater? Because someone could have written a new value in between requests to write and read model. The server can then do two things. It can either return the data or fail because it has not received expected event yet. The important is that the server knows that the value will be delivered just soon. That is a powerful information, because the server can return Retry-After X seconds HTTP header. Client's browser will (or should) retry the request after X seconds, so that the initial failure is transparent to the client. To cut it short:
- Issue a command to write model
- Read current version from ACK
- Put expected version to request to read model
- Expect data or expect browser to retry soon transparently (because of Retry-After header set by read model server)
Let's see how read model server can implement that logic. First we have to create an endpoint for querying a particular shop item by UUID. We will use Spring Boot.
@RequestMapping(method = RequestMethod.GET, value = "/{uuid}")
public ResponseEntity<ShopItem> readById(
@PathVariable String uuid,
@RequestHeader(value="Expect") Integer expectedVersion) {
//..
}
But how do we pass expected version in the request to the read model? One option is to put it as request parameter and query under URL /uuid?expectedVersion=2, when we expect version number equal of greater than 2. The other option is to use HTTP header. Which one? There actually is one called EXPECT. According to <a href=https://tools.ietf.org/html/rfc7231#section-5.1.1">RFC7231</a> it is used to:
The "Expect" header field in a request indicates a certain set of behaviors (expectations) that need to be supported by the server in order to properly handle this request.
To align more with HTTP, let's put expected version under EXPECT parameter instead of request parameter. We do test first. When expected version is greater than current version we expect that server says Retry-After 2 seconds.
def 'should ask to retry after when state is not yet present'() {
given:
UUID itemUUID = UUID.randomUUID()
itemIsOrderedAtVersion(itemUUID, ANY_TIME, currentVersion)
when:
ResultActions result = mockMvc
.perform(get("/${itemUUID}")
.header(EXPECT, expectedVersion))
then:
result.andExpect(header().longValue("Retry-After", 2))
result.andExpect(status().isServiceUnavailable())
where:
currentVersion || expectedVersion
1 || 2
2 || 3
4 || 10
100 || 201
}
The second scenario ensures that when expected version is smaller or equal to current version, we return the data.
def 'should return the data when expected version is equal or smaller than current version'() {
given:
UUID itemUUID = UUID.randomUUID()
itemIsOrderedAtVersion(itemUUID, ANY_TIME, currentVersion)
when:
ResultActions result = mockMvc
.perform(get("/${itemUUID}")
.header(EXPECT, expectedVersion))
then:
result.andExpect(status().isOk())
where:
currentVersion || expectedVersion
2 || 2
3 || 3
40 || 10
1000 || 201
}
Now let's take a look at the endpoint implementation. The client can leave expected version as empty. Let's assume that when it is not defined then the data is as good as it gets - the recent one.
@RequestMapping(method = RequestMethod.GET, value = "/{uuid}")
public ResponseEntity<ShopItem> readById(
@PathVariable String uuid,
@RequestHeader(value=HttpHeaders.EXPECT) Integer expectedVersion) {
final ShopItem item = jdbcReadModel.getItemBy(UUID.fromString(uuid));
if (dataAtExpectedState(item, expectedVersion)) {
return ResponseEntity.ok(item);
}
return retrySoon();
}
private boolean dataAtExpectedState(ShopItem item, Integer expectedVersion) {
return expectedVersion == null || expectedVersion <= item.getVersion_value();
}
private ResponseEntity<ShopItem> retrySoon() {
final HttpHeaders headers = new HttpHeaders();
headers.set(HttpHeaders.RETRY_AFTER, Integer.toString(2));
return new ResponseEntity<>(headers, HttpStatus.SERVICE_UNAVAILABLE);
}
The last scenario ensures that after retrying client gets expected data. Of course, if read model was updated in between two requests.
def 'should return the data after retrying'() {
given:
UUID itemUUID = UUID.randomUUID()
itemIsOrderedAtVersion(itemUUID, ANY_TIME, 1)
when:
ResultActions result = mockMvc
.perform(get("/${itemUUID}")
.header("Expect", 2))
then:
result.andExpect(header().longValue("Retry-After", 2))
result.andExpect(status().isServiceUnavailable())
when:
itemIsPaidAtVersion(itemUUID, ANY_TIME, 2)
and:
ResultActions secondResult = mockMvc
.perform(get("/${itemUUID}")
.header("Expect", 2))
then:
secondResult.andExpect(status().isOk())
}
This was an example of using Http Headers (Expect and Retry-After) to implement transparent retries and ensure "read your own writes" in eventually consistent system.
The other option is to inform the user that we are only able to return data from a concrete point of time (our last known update). The read model can keep track of when a concrete event stream was recently updated. On the screen, next to our data there can be a time-stamp which says how stale it is. This is actually pretty easy to introduce by the means of <a href="https://tools.ietf.org/html/rfc7232#section-2.2"Last-Modified</a> HTTP Header. Take a look at the test:
def 'should return last modified date in response'() {
given:
UUID itemUUID = UUID.randomUUID()
itemIsOrderedAtVersion(itemUUID, ANY_TIME, 1)
when:
ResultActions result = mockMvc
.perform(get("/${itemUUID}")
.header("Expect", 1))
then:
result.andExpect(
header()
.string(
LAST_MODIFIED,
HTTP_DATE_FORMAT.format(from(ANY_TIME))))
result.andExpect(status().isOk())
}
And we had to modify previous implementation, so that it returns new header:
@RequestMapping(method = RequestMethod.GET, value = "/{uuid}")
public ResponseEntity<ShopItem> readById(
@PathVariable String uuid,
@RequestHeader(value= EXPECT) Integer expectedVersion) {
final ShopItem item = jdbcReadModel.getItemBy(UUID.fromString(uuid));
if (dataAtExpectedState(item, expectedVersion)) {
return okWithLastModifiedDate(item);
}
return retrySoon();
}
private ResponseEntity<ShopItem> okWithLastModifiedDate(ShopItem item) {
final HttpHeaders headers = new HttpHeaders();
headers.set(
HttpHeaders.LAST_MODIFIED,
HTTP_DATE_FORMAT.format(item.getLastModifiedDate()));
return new ResponseEntity<>(item, headers, HttpStatus.OK);
}
With this behavior, we can notify our client that the data he is seeing might be a little stale, so he might refresh the browser. Be careful here. A common mistake in a read model is to save last updated date as a process date (arrival date). Our real model can be down for 2 days and when it gets up again it will process events that happened 2 days ago. That would in turns display wrong information to a client - the date is actually 2 days older. We always have to take into account the date of the creation of an event, which is passed to the read model.
The last option is tricking the user directly in the client UI. As soon as we got the ACK, we know the data will be eventually in the read model. So we might directly modify our temporal view in web browser and hope that user will not refresh the page until expected version arrived in read model. This is rather rare way of dealing with eventual consistency.
Couple of notes
How we return current version in ACK from write model? Most often custom return type is introduced - it contains status code and the current version. Another way is to use the E-tag HTTP header, which <a href=https://tools.ietf.org/html/rfc7232#section-2.3.1> according to specification</a> can be used for:
"The "E-Tag" header field in a response provides the current entity-tag for the selected representation, as determined at the conclusion of handling the request. An entity-tag is an opaque validator for differentiating between multiple representations of the same resource, regardless of whether those multiple representations are due to resource state changes over time, content negotiation resulting in multiple representations being valid at the same time, or both."
As it is described, the value should be opaque, so we should encrypt our version parameter. We don't want to reveal how big our event-stream is and how it is build due to the security reasons. The same should be actually done when we query read model and specify expected version.
RFC also says that we can specify concrete time in Retry-After header. We should avoid that, because this can result in very high traffic at this specific time. Imagine we inform many of our clients to retry at a specific time. Although the clocks of the clients are not synchronized, the traffic around that time can be significant.
Sadly although both Mozilla and Chrome ensure supporting Retry-After header, it does not work in the newest versions. The browsers do not care that much, because the servers rarely send that header. It creates an endless circle. But remember, the client is not always a browser. So it is good to have Retry-After header.
Code can be found here
